In the last post
about configuring WebLogic Server time zone, I mentioned one of reasons you do it is to configure the default time zone for ADF Faces to convert date and time for input and output components. This post will focus on it - how the ADF Faces convertDateTime converter and the af:convertDateTime tag work with the time zone configuration in detail. This is only the first piece of the puzzle. Hopefully, I can put other pieces together to complete the puzzle with another two or more subsequent posts.
Here you can find the Source Code of the sample application or Download ZIP of it.
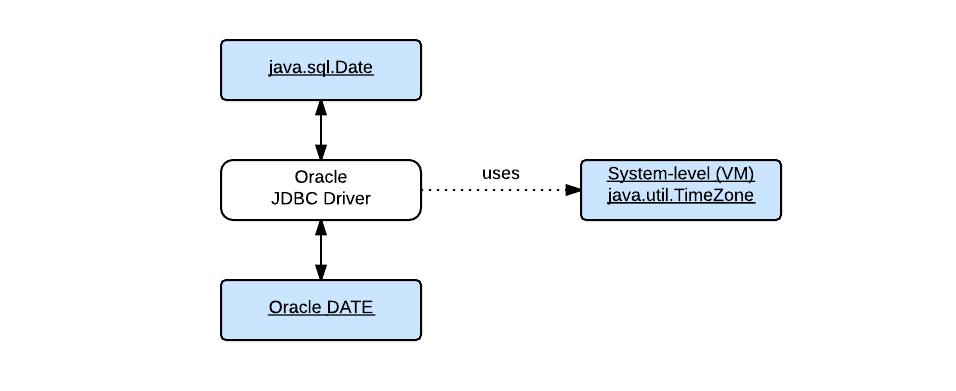
To make it easier, I'm using java.util.Date in the discussion and the sample application, and Oracle data type DATE in some figures. The basic idea applies to java.sql.Date, etc.
In Java, the class java.util.Date represents a specific point in time. As per the javadocs for one of its constructors - Date(long date):
Allocates a Date object and initializes it to represent the specified number of milliseconds since the standard base time known as "the epoch", namely January 1, 1970, 00:00:00 GMT.
Clearly, the class Date represents a determinate point in time which is in the time zone GMT. To display a Date, we need a converter or a formatter to turn the Date into a String which represents the "wall clock time" local to a specific time zone. When the target time zone changes, the resulting String or the "wall clock time" could change, but the value of the Date does not change in this process.
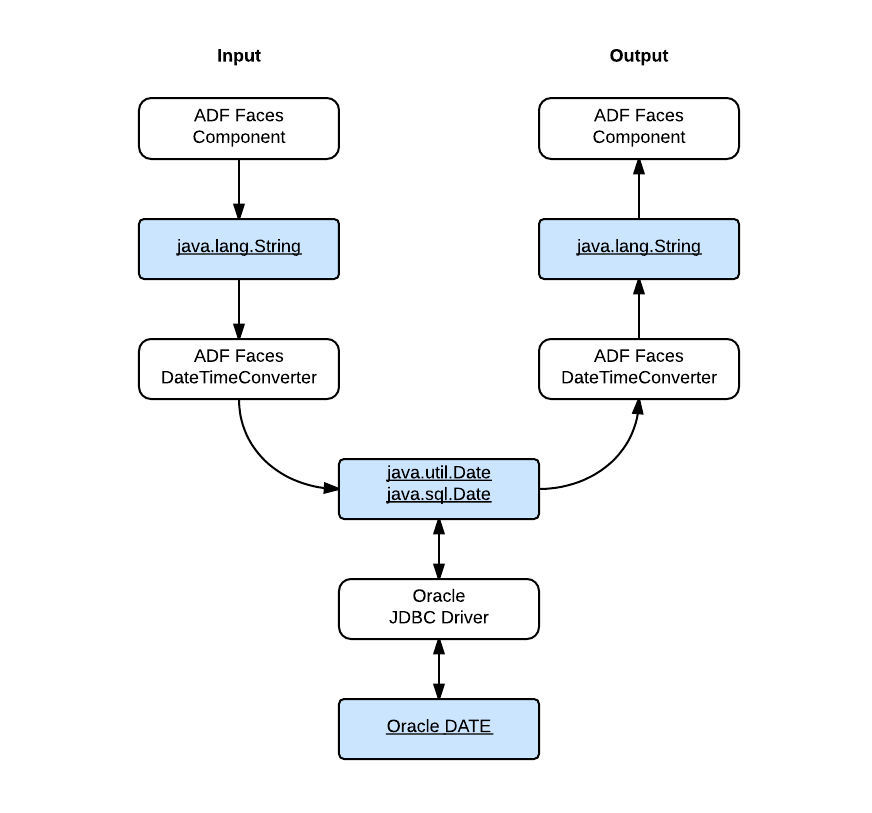
The following figure illustrates how the date and time data passes through a typical ADF application:
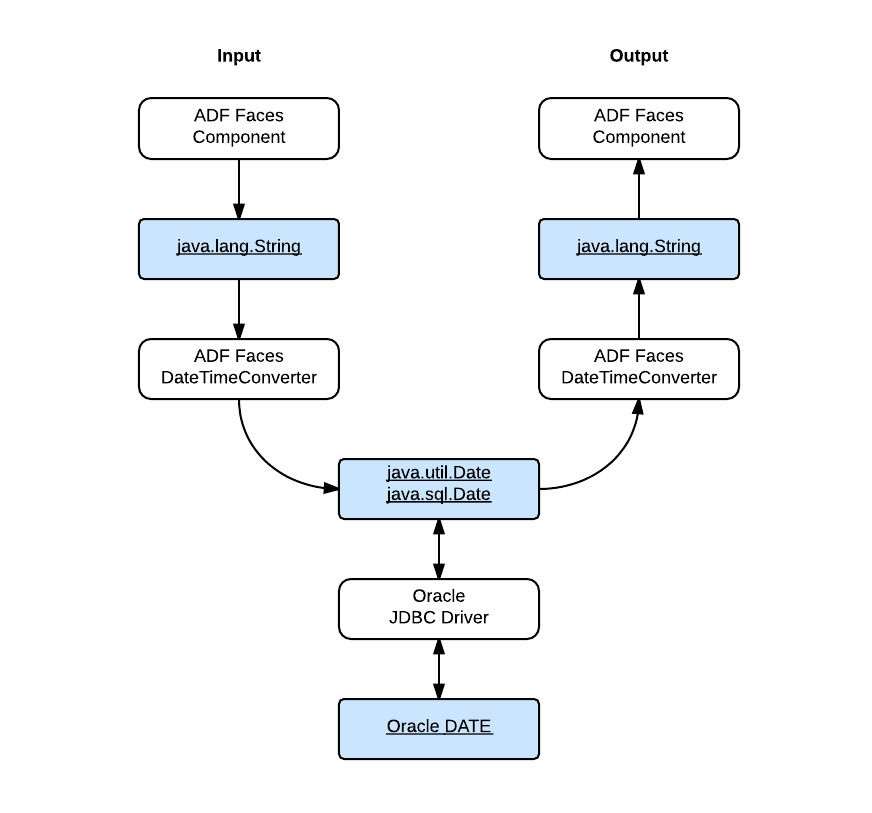
- The ADF Faces component accepts the user input as a
String value and convert it into a Java Date value with a DateTimeConverter.
- The Oracle JDBC driver passes the
Date value into the database as an Oracle DATE value.
- For output, the JDBC driver retrieves the Oracle
DATE value out of the datebase as a Java Date value.
- The ADF Faces component display the date and time after converts the Java
Date value into a String value with a DateTimeConverter.
I'll talk about the JDBC part in my next post, and here will focus on how the time zone configuration comes into play in the view part:
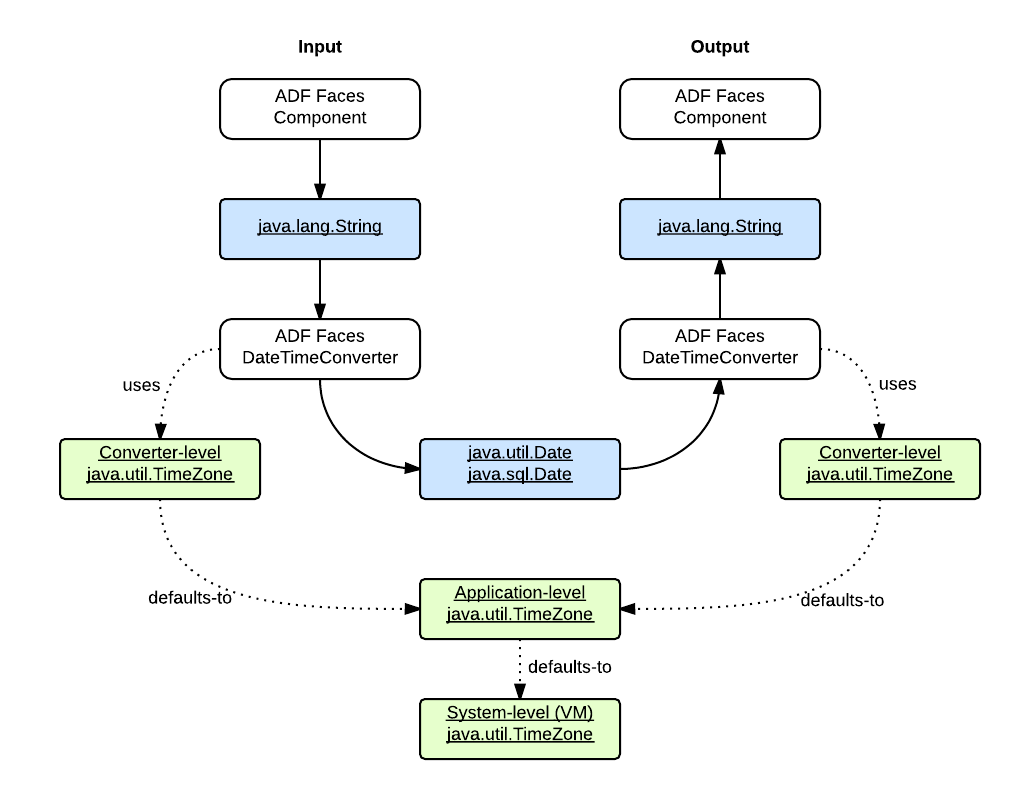
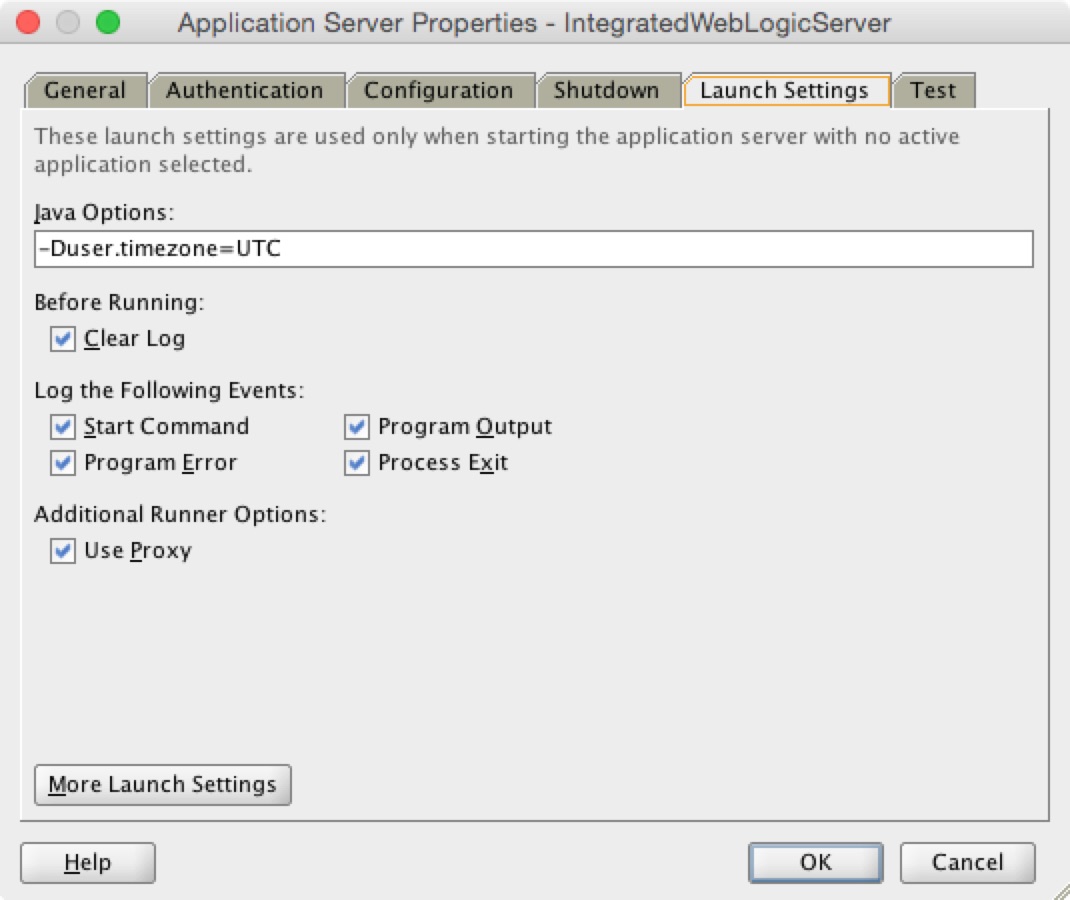
When an ADF Faces component works with a DateTimeConverter, a java.util.TimeZone object can be configured with it, as shown in the following code snippet from the sample application:
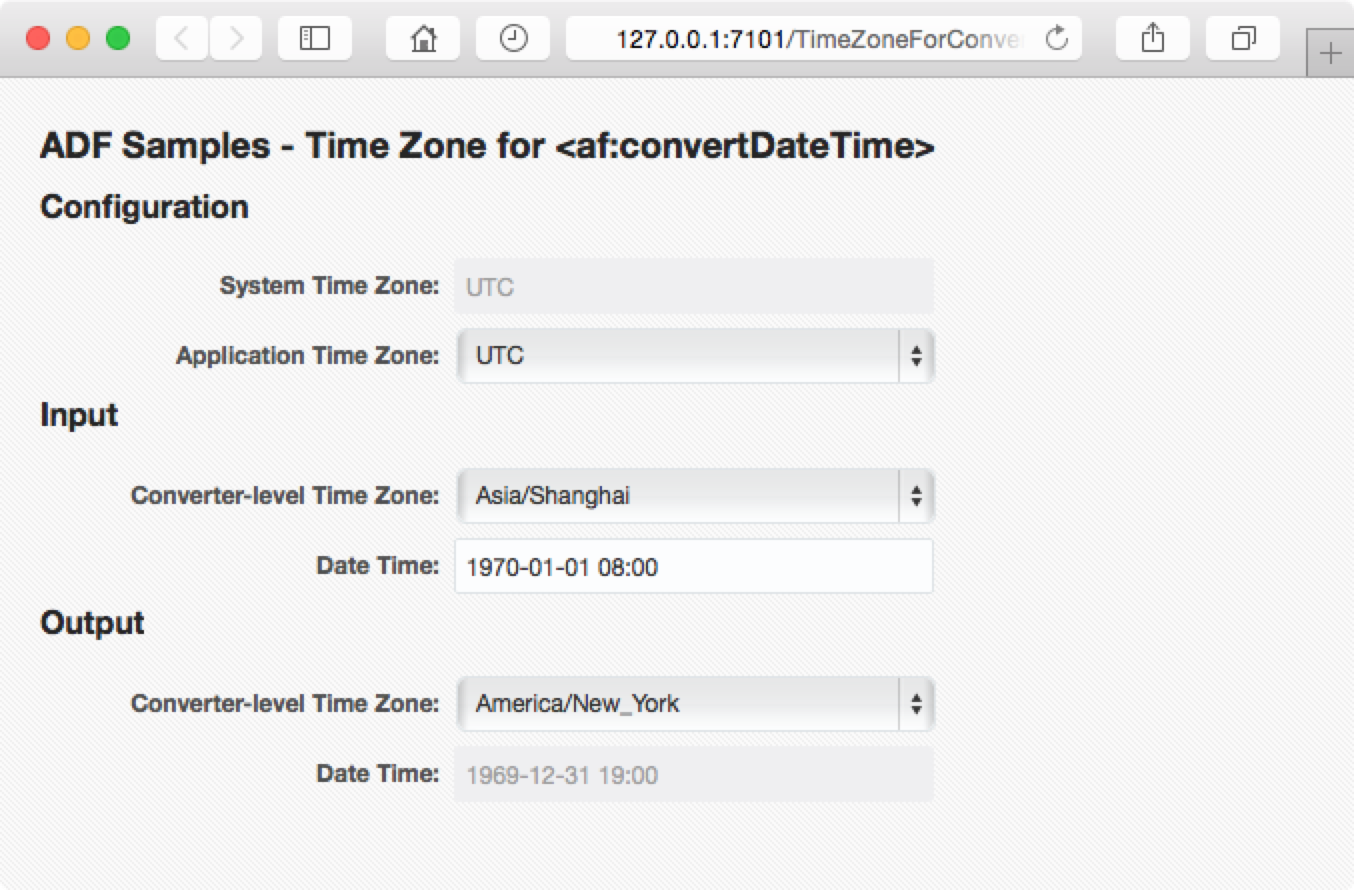
<af:inputText
id="it_dt"
label="Date Time: "
value="#{userBean.dateTime}" autoSubmit="true">
<af:convertDateTime
pattern="yyyy-MM-dd HH:mm"
timeZone="#{userBean.inputTimeZone}"/>
</af:inputText>
Here's the description from ADF RichClient API - <af:convertDateTime> for the timeZone attribute:
Time zone in which to interpret any time information in the date string. If not set here, picks this value from trinidad-config.xml configuration file. If not defined there, then it is defaulted to the value returned by TimeZone.getDefault(), which is usually server JDK timezone.
When the component is used for user input, the TimeZone object specifies the source time zone in which the date string should be interpreted, and convert the String input value into a Date value which is in the destination time zone GMT. When the component is used for output, the TimeZone object specifies the destination time zone, and the Date value is converted into a String representing the local date and time in the time zone specified by the TimeZone object.
You can configure the time zones in three levels:
- System-level time zone
- Application-level time zone
- Converter-level time zone
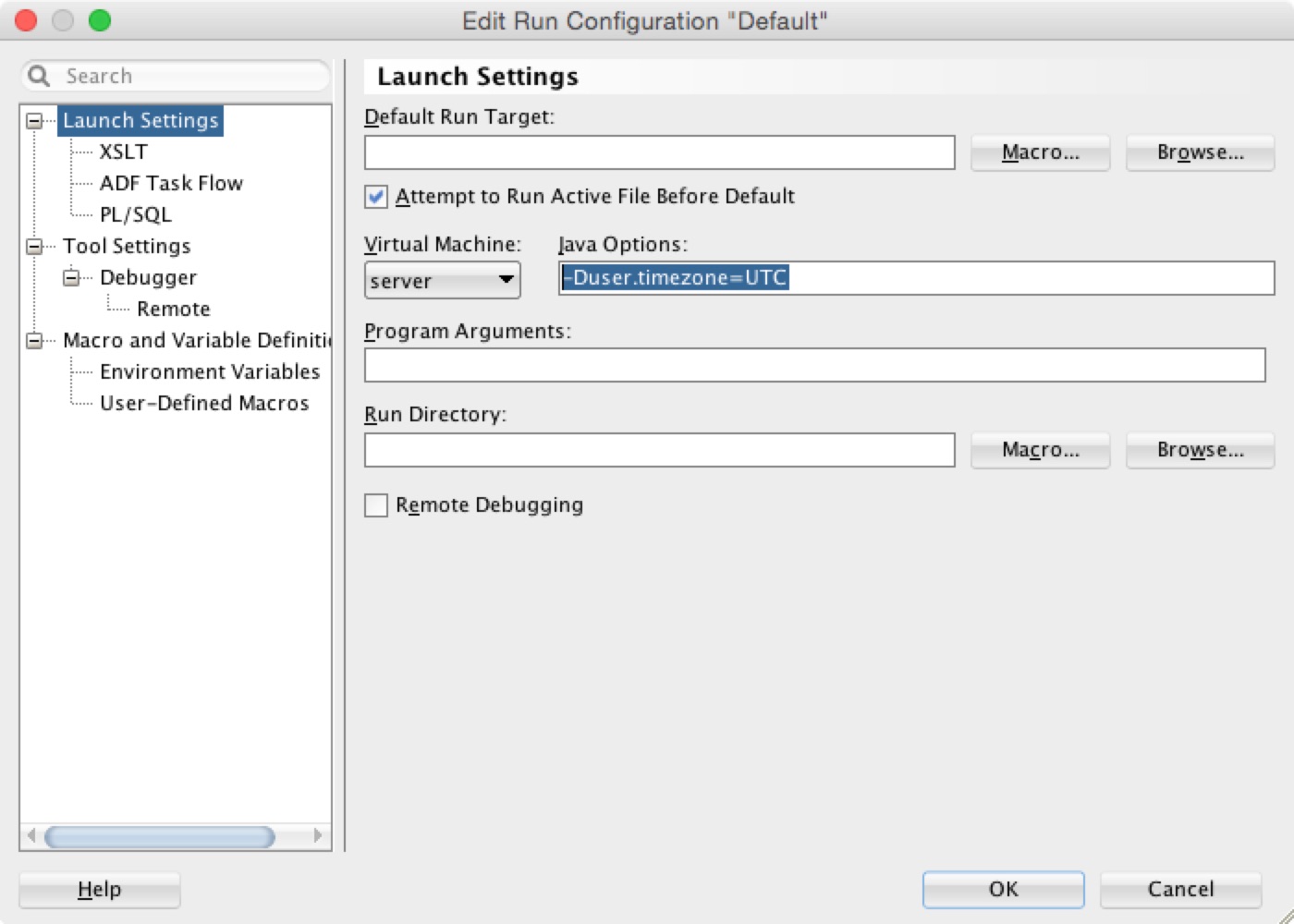
The system-level time zone can be configured as described in my last post - Configuring the Time Zone with WebLogic Server. The application-level time zone can be configured like this as in the sample application:
<trinidad-config xmlns="http://myfaces.apache.org/trinidad/config">
<time-zone>#{applicationBean.applicationTimeZone}</time-zone>
</trinidad-config>
The converter-level time zones can be configured with business-specific time zones or user preference time zones according to your application requirement. For example, in an application displaying a flight's departure time and arrival time, two different time zones for the departure airport and arrival airport respectively can be used. That's the business-sepcific time zone approach. You can also support the user preference time zones in this case as an user-friendly feature.
This post covers how the time zones participate in the date values processing in the ADF Faces view layer. In the next post, I'll introduce what happens when the date values are accessed with the Oracle JDBC driver.
Special Note for the ADF prior to 12c
In the ADF 11g, the timeZone attribute of the af:convertdateTime is documented as this:
Time zone in which to interpret any time information in the date string. If not set here, picks this value from adf-faces-config.xml configuration file. If not defined there, then it is defaulted to GMT.
Series on Time Zone
Sample Application
Environment
- Oracle Alta UI
- JDeveloper 12.1.3.0.0 Build JDEVADF12.1.3.0.0GENERIC_140521.1008.S
- Safari Version 8.0
- Mac OS X Version 10.10
Resources